Machine Learning Model Monitoring: What to Do In Production
 Kim Harrison
Kim Harrison
Machine learning model monitoring is the process of continuously tracking and evaluating the performance of a machine learning model in production. This involves using various techniques to detect and measure issues that may arise with the model over time, such as model degradation, data drift, and concept drift. MLOps teams use monitoring to track a model’s operational performance over time, often using languages like Python and R.
Key aspects of model monitoring include monitoring key performance metrics, drift detection, bias and fairness, explainability, and putting alerts into place that will notify when issues are detected. By effectively monitoring ML models, organizations can ensure that their models remain accurate, reliable, and fair over time.
Why Machine Learning Model Monitoring in Production Matters
Building and shipping a machine-learning model takes considerable time and effort. Once you have a live-in-production model, it should be continuously monitored. This is for the same reason we built the models in the first place–these are powerful models that provide a wealth of information to the user, and they are only as good as the information they deliver. By continuously monitoring models, organizations can proactively address issues and ensure that their models remain effective and reliable in production.
There are multiple reasons why models need to be monitored, including:
Model Degradation
Over time, models can become less effective due to various factors, such as hardware limitations, software updates, user behavior, or other external factors. A degraded model may provide erroneous or less valuable insights, and could impact business outcomes that rely on that information–and teams should look to debug poorly-performing models as soon as possible.
Data Drift
The characteristics of the data a model is trained on can change over time, as can the way a model handles feature attribution–how much each feature in your dataset contributes to a prediction. This can lead to the model's performance degrading as it encounters new, unseen data from new data sources or diverges from what should be a relevant subset. To ensure a model continues to provide value, it is important to remember to update it with new data as relevant.
Concept Drift
When the underlying relationships between the input features and the target variables change, this could mean a model's assumptions are no longer valid. For example, in a model predicting customer behavior, changes in economic conditions or customer preferences could make past patterns irrelevant. Retraining the model and updating data can help address concept drift.
Bias and Fairness Issues
Models can inadvertently perpetuate biases present in the training data. Monitoring helps identify and address bias. (Early in the launch of generative AI, large language models (LLMs) were infamously plagued with bias issues.) If not addressed, bias in models can have serious ethical and legal implications, especially if the model is serving sensitive areas like hiring, lending, or healthcare.
Explainability
Understanding how a model makes decisions is crucial for ensuring its reliability and fairness. Monitoring can help identify unexpected or undesirable behaviors.
Operational Failures and Latency Issues
Once a model is in production, it may encounter operational issues such as slow response times, system crashes, or scaling inefficiencies. Monitoring ensures the model continues to deliver predictions within the required time frames and scales appropriately with demand. This is critical in real-time or high-throughput applications.
Compliance and Regulatory Requirements
In many industries, there are regulations that require organizations to monitor and explain the decisions made by their systems. Monitoring helps demonstrate that the model remains compliant with relevant laws and standards, reducing the risk of penalties or legal challenges.
Security and Privacy Concerns
Machine learning models in production are vulnerable to attacks, such as when malicious actors introduce misleading data to compromise the model. Monitoring for unusual model inputs and behaviors can help detect and mitigate security threats to the model.
Resource and Cost Optimization
Deployed models use compute resources such as CPU, GPU, and memory. Without proper monitoring, inefficient models can lead to higher operational costs or even system failures due to resource exhaustion, which can affect the overall pricing of your project. Monitoring these resources can help optimize performance and costs, especially in large-scale deployments or cloud environments.
Performance Monitoring for Business Impact
Business goals and metrics, such as customer satisfaction or conversion rates, may depend on the performance of the model. Monitoring helps ensure the model contributes positively to key business outcomes.
Customer Trust and Experience
If a model starts producing inaccurate or slow predictions, customers may lose trust in the system. Continuous monitoring helps identify and troubleshoot issues before they impact the user experience. Maintaining high model performance ensures consistent, high-quality results, which is key to building and maintaining user trust.
Cross-functional Strategy for Model Monitoring
When building out a monitoring program, it’s important to consider all the stakeholders who should be involved. It’s easy to assume this would fall solely on the engineering team that built and/or shipped the model to production. However, there are many aspects of a machine learning model that should be monitored.
Engineering may have systems that can continuously monitor for operational issues. Data scientists may need to be involved when considering training data to evaluate datasets (including cleansing and profiling feature values). Customer success should be included when strategizing customer satisfaction metrics. Product and legal may need to be involved with compliance monitoring, explainability, and biases and fairness issues.
As you build your program, consider not only who can help instrument the appropriate signals, but also who will need to be notified when issues arise as part of your workflow. This will ensure you not only have a more comprehensive monitoring program, but your organization will be better prepared to respond quickly and efficiently when issues do arise.
Where Model Monitoring Fits Into the ML Lifecycle
The machine learning lifecycle refers to the end-to-end process involved in developing, deploying, and maintaining a machine learning model. It includes various stages, starting from identifying a problem, to the management and updating of your production model, and even retirement. The stages include:
- Problem Definition: Clearly define the business problem or use case that machine learning is intended to solve.
- Data Collection and Preparation: Gather the necessary data. Clean, preprocess, and transform it to make it suitable for modeling.
- Model Development: Choose the most appropriate machine learning algorithms based on the nature of the problem and data. Train the model using the training dataset.
- Model Evaluation: Evaluate the trained model’s performance on a separate validation or test dataset.
- Hyperparameter Tuning: Optimize the model by adjusting hyperparameters (parameters not learned during training) for better performance.
- Model Deployment: Deploy the trained and validated model into a production environment where it can make real-world predictions.
- Model Monitoring and Maintenance: Continuously track model quality and performance, detect any drift or performance degradation, and ensure it meets operational requirements.
- Model Retraining (and Feedback Loop): Retrain the model as needed to adapt to new data (and/or data types), changes in the environment, or evolving requirements.
- Model Retirement: Decommission a model when it is no longer effective, relevant, or required.
The lifecycle ensures that a model is built systematically, deployed effectively, and monitored continuously so that it can continue to meet evolving requirements. It is iterative, meaning a model may need to be retrained or updated as new data becomes available or as requirements change. To ensure the model is effective at solving the business problem or use case, it is important to continuously monitor it and incorporate feedback back into it.
Monitoring enters the later stages of the ML project lifecycle post-deployment, and helps MLOps teams iteratively detect issues and improve performance over time."
How ML Model Monitoring Compares to Overlapping Processes
When we talk about machine learning model monitoring, there are processes that overlap with other monitoring efforts that may already be in place. Most software development teams already have monitoring programs in place as they have a responsibility to provide stable, reliable systems. They are often bound by security requirements, compliance regulations, and ultimately dedicated to delivering a positive experience.
Because of this overlap, some teams use monitoring and/or observability systems already in place to support their machine learning model monitoring strategy. However, for some processes entirely new tools and techniques may need to be added. Areas in a monitoring system where these techniques and processes overlap include:
Software Monitoring & Observability
Monitoring and observability are related but distinct concepts that help ensure the health, performance, and reliability of applications and infrastructure. They both aim to detect issues and provide insights into the behavior of systems, but they do so at different levels of depth and with different approaches.
Monitoring is the process of collecting and analyzing data about a system's performance and behavior. Its focus is primarily on collecting metrics like CPU usage, memory consumption, network traffic, and error rates.
Observability is the ability to understand a system's internal state based on its external outputs. Its focus is beyond metrics. Rather observability encompasses understanding the relationships between different components, diagnosing issues, and predicting future behavior. To achieve observability, teams often use distributed tracing tools that provide insights into the flow of requests through a system.
In essence, monitoring provides the "what" (metrics), while observability provides the "why" (understanding the underlying causes of issues).
Data Monitoring
Data monitoring refers to the practice of continuously observing and analyzing data to ensure its quality, integrity, and consistency. It involves tracking data flow, detecting anomalies, and identifying potential data quality issues that could impact the system's performance or accuracy.
Key aspects of data monitoring include data quality, in which teams make sure that data is accurate, complete, and consistent. Data integrity, where data is protected from unauthorized access, modification, or deletion. Data consistency, in which teams verify data is consistent across different systems and databases. Data anomalies, where teams detect and address unusual or unexpected data patterns. And data lineage, in which teams track the origin and transformation of data throughout its lifecycle.
Experiment Tracking
Experiment tracking in software development, particularly in the context of machine learning and data science, refers to the practice of systematically recording and organizing information about experiments conducted during the development process. This includes experiment details, the datasets used for training and testing, the results or outcomes of the experiment, and any additional observations.
Experiment tracking is important because it allows researchers to replicate experiments and verify results. By documenting experiments, developers can avoid repeating mistakes or inefficient approaches. It also facilitates collaboration among team members by providing a shared understanding of the project's progress. Furthermore, the data can be analyzed to identify trends, patterns, and areas for improvement.
Machine Learning Model Observability
Machine learning model observability is the ability to understand a machine learning model's internal state and behavior based on its external outputs. It involves tracking and analyzing various aspects of a model's performance and behavior over time to ensure its reliability, accuracy, and fairness.
Key components of model observability include model performance metrics, data drift, concept drift, bias and fairness, explainability, and setting up alerts to notify relevant stakeholders when issues are detected. Tools and techniques utilized for model observability include model monitoring platforms, data drift detection algorithms, explainable AI techniques, and bias detection tools.
Machine Learning Model Governance
Machine learning model governance is a set of processes, policies, and practices designed to ensure that machine learning models are developed, deployed, and managed in a responsible, ethical, and effective manner. It involves establishing guidelines for model development, deployment, and monitoring to ensure that models meet quality standards, comply with regulations, and align with organizational objectives.
Key components of model governance include model development standards, procedures for deployment and monitoring, risk management practices, ethical considerations, compliance, and governance frameworks.
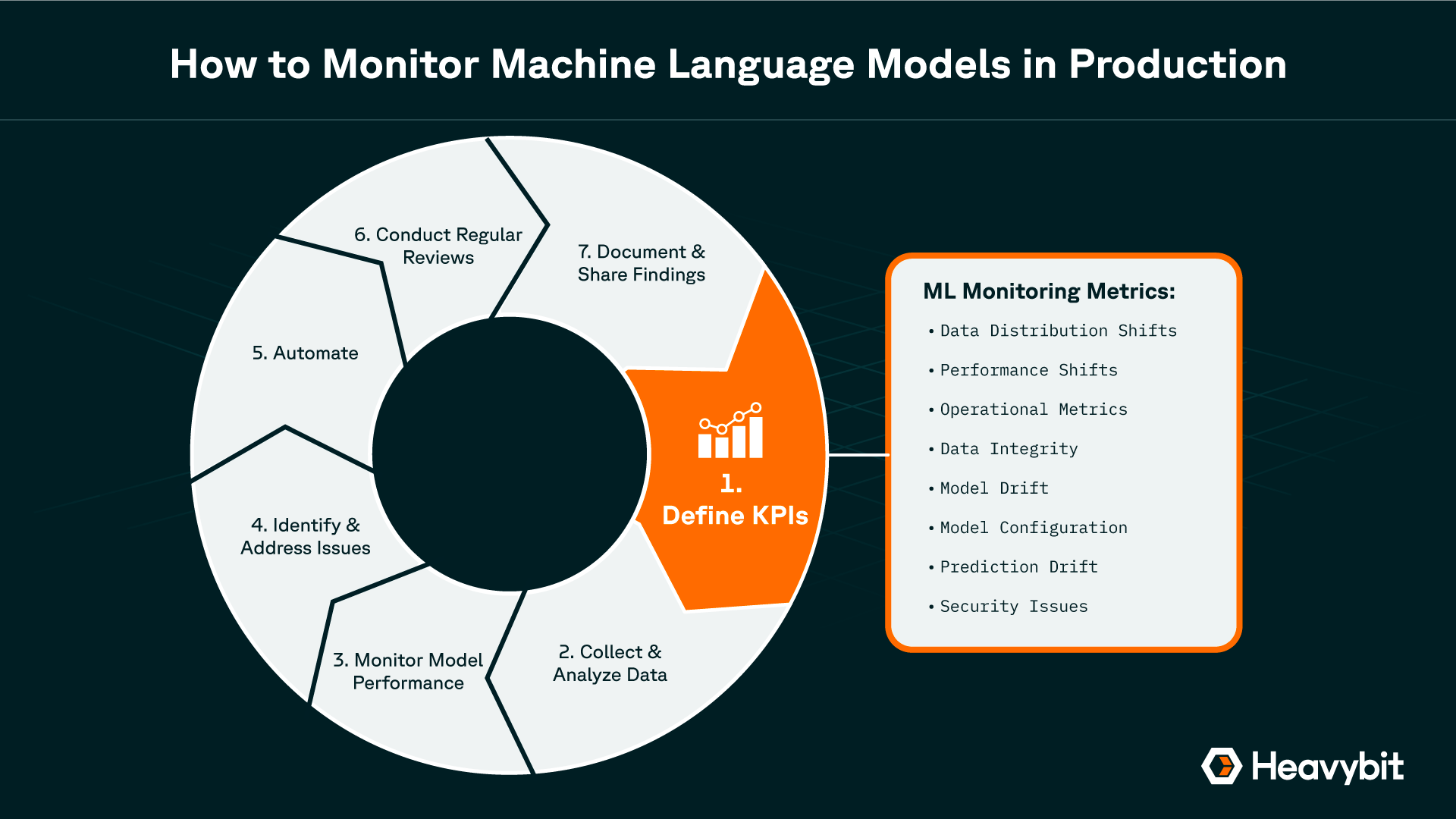
How to Monitor Machine Learning Models in Production
>> Click to zoom in on this infographic
The steps involved in monitoring ML models, including key metric classes.
How to Start Monitoring ML Models in Production
Monitoring machine learning models in production is critical to ensure their continued effectiveness and reliability. Once deployed, models are exposed to real-world data, which can differ from the training data. Furthermore, changes in the environment may cause model performance to degrade. A robust monitoring process helps to identify and address these issues before they affect business outcomes.
There are many elements to consider when building a monitoring program. It will likely look different for different teams, depending on the applications they are managing and services providing. Here's a framework that can be used as a starting point for building a monitoring strategy:
1. Define Key Performance Indicators (KPIs)
Choose relevant metrics that align with your model's objectives. Consider how these align with higher level business objectives, and where key stakeholders across the organization can be included. Establish baseline values for your KPIs to measure performance against.
2. Collect and Analyze Data
Continuously collect data from your production environment. Use statistical methods and data visualization techniques to identify trends, anomalies, and deviations from expected behavior. Be sure to consider what monitoring and observability programs already exist within the organization that can contribute to this effort. What tools and techniques are in place, versus what needs to be incorporated to provide a more complete picture.
3. Monitor Model Performance
Regularly monitor your selected KPIs to assess model performance. Compare current performance to established benchmarks to identify significant changes. Use statistical methods to detect unusual patterns or outliers in the data.
4. Identify and Address Issues
If anomalies are detected, investigate their root causes. When necessary, retrain the model with updated data or explore alternative algorithms. Take appropriate steps to address identified issues and improve model performance. This includes notifying key stakeholders across the organization, often outside of engineering. It’s important that team members are aware of issues, and are available to provide insights and/or feedback to help address issues more efficiently.
5. Automate Monitoring
Leverage monitoring tools and platforms to automate data collection, analysis, and alerting. Configure notifications for relevant stakeholders when performance metrics deviate significantly from benchmarks.
6. Conduct Regular Reviews
Evaluate model effectiveness. Periodically review the model's overall effectiveness and alignment with business objectives. Adjust monitoring strategies as needed to reflect changes in data, requirements, or model performance.
7. Document and Share Findings
Document monitoring results, analyses, and corrective actions. Share findings with relevant stakeholders to facilitate informed decision-making.
By having a clear, well-defined process for monitoring and alerting, organizations can quickly detect issues and ensure the continuous delivery of valuable predictions, while adapting models to changes in real-world conditions.
What Metrics Should You Monitor for ML Models?
The process for monitoring machine learning models in production ensures that models remain accurate, fair, and operationally efficient by tracking specific model metrics. To clarify, monitoring happens after you collect your dataset, fine-tune your model, and deploy to production. The goal is to monitor not only the model's performance but also the input data, operational metrics, and system infrastructure. Here are some common monitoring metrics and techniques.
Data Distribution Shifts
When monitoring models for data distribution shifts (commonly known as data drift), it's crucial to track changes in the statistical properties of the input data that differ from the data used to train the model. A shift in the data distribution can degrade model performance because the model was trained on a different data distribution and may not generalize well to the new data. Some key metrics and approaches include:
- Summary Statistics such as mean and variance, min max and range, and standard deviation
- Histograms or Probability Density Functions to visualize the distribution of features
- Kolmogorov-Smirnov (KS) test to compare a feature's current distribution from its distribution in the training data
- Chi-Square Test for categorical features
- Population Stability Index (PSI) to measure differences between datasets
- Jensen-Shannon (JS) Divergence to quantify the similarity between two probability distributions
- Hellinger Distance to compare distributions
- Earth Mover’s Distance (EMD) often used in scenarios with continuous or ordered data
- P-Values for individual features
- Correlation Shifts to see if a relationship has changed over time
- Model-Specific Feature Importance Drift to detect if the model is relying on different data patterns than it was during training
- Target Distribution Monitoring to detect underlying changes in data patterns
Performance Shifts
When monitoring models for performance shifts in production, it is essential to track metrics that show if the model is operating accurately and reliably over time. Performance shifts can occur due to changes in data distribution, evolving real-world conditions, or system issues. Here are some key metrics to monitor:
- Prediction Accuracy to see the proportion of correct predictions made by the model
- Precision, Recall and F1 Score provide a more nuanced view of performance than accuracy, especially for imbalanced datasets
- Area Under the ROC Curve (AUC-ROC) to better understand the model's ability to separate classes over time
- Area Under the Precision-Recall Curve (AUC-PR) highlights how well a model performs with respect to false positives and false negatives
- Log Loss (Cross-Entropy Loss) to indicate if a model is becoming less certain about its predictions
- Mean Squared Error (MSE) or Root Mean Squared Error (RMSE) to see if a model's predictions are drifting from actual values
- Mean Absolute Error (MAE) provides insight into how far off a model's predictions are from true values
- Bias and Variance to detect shifts in model generalization
- Model Drift (Concept Drift) to understand when the relationship between input data and target predictions drift, indicating a need to retrain or update the model
- Calibration to see how well the predicted probabilities align with observed outcomes
- Class Distribution Monitoring to better understand if the model is becoming biased
- Inference Time (Latency) to understand the time a model takes to make predictions
- Throughput to understand the number of predictions a model can make per minute
- Model Resource Usage which measures CPU, memory, and GPU by the model during inference to better understand efficiency
- Error Rates and Outliers to better understand changes in the model's error rate
Operational / Health Metrics
When monitoring operational/health metrics for machine learning models, the goal is to ensure that the model functions smoothly within the production environment, and that it operates efficiently, reliably, and at scale. These metrics focus on the infrastructure, system performance, and the model’s ability to meet the requirements for latency, scalability, and resource utilization.
Here are the key metrics to monitor:
- Latency (Inference Time) to understand how long the model takes to process and input and return a prediction
- Throughput to understand the number of predictions a model can make per minute
- Uptime or Availability showing the percentage of time the model is operational
- Error Rate to understand the proportion of failed model predictions, including system errors, invalid inputs, or unhandled exceptions
- Memory Usage to understand the amount of memory the model consumes during inference
- CPU and GPU Utilization to understand the percentage of CPU and GPU used by the model during inference
- Disk I/O shows the rate of reading from or writing to disk, showing data pipeline efficiency
- Network Latency and Bandwidth to understand the time it takes for data to travel and understand how close to realtime the model is
- Request Rate (QPS/RPS) to understand the number of queries or requests the model receives per second
- Queue Length (Backlog of Requests) to know the number of unprocessed requests waiting to be handled
- Autoscaling Events to understand the frequency and conditions in which the model scales
- Cold Start Times to understand how long it takes for the model to load and start making predictions after being deployed or scaled
- Job Completion Time to understand time needed for batch predictions
- Model Loading Time to understand time needed to load the model from storage into memory for inference
- Model Versioning and Rollbacks to be sure the correct version is in production
- Health Check Failures to know the number of times a model fails basic health checks, such as connectivity or availability
- Log Analysis (Error and Warning Logs) to know the number of error or warning logs generated by the system
- Deployment Success and Failure Rates to understand if versions have been deployed successfully or not
It’s important to confirm metrics prior to starting the ML monitoring process, and it can be helpful to iteratively track performance progress against metrics to ensure data quality remains high and models and their predictions don’t drift off-course."
Data Integrity
Monitoring data integrity is essential to ensure that the data feeding into a model remains clean, consistent, and relevant. Data integrity issues can lead to degraded model performance, erroneous predictions, or biased outcomes. Monitoring data integrity involves tracking various aspects of the input data, from format and schema validation to completeness, consistency, and correctness.
Here are key metrics to monitor:
- Missing Data the percentage of missing values to ensure the data pipelines are functioning correctly
- Duplicate Data that may distort a model's understanding of patterns in the data
- Data Completeness understanding non-missing and valid entries to ensure the model returns accurate predictions
- Data Consistency ensuring data adheres to predefined rules/formats
- Outlier Detection understanding the data points that fall outside the expected range of distribution, which could lead to erroneous predictions
- Feature Distribution Drift (Data Drift) to better understand if the current data has drifted from the training data
- Target Distribution Drift which could signal underlying changes in the environment and a potential need for retraining
- Schema Validation ensures incoming data conforms to the expected schema, a mismatch could cause model errors
- Range Validation to ensure the values in the input data fall within accepted bounds so as not to distort the model
- Categorical Value Consistency ensuring there are no unexpected values that may lead to errors
- Data Freshness / Timeliness to ensure that the model is working on fresh data and can provide more accurate predictions
- Data Volume which shows the amount of data ingested into the model over time
- Data Integrity Checks (Checksums / Hashes) which helps detect corruption early
- Encoding and Format Validation because incorrect encoding or formats can lead to errors in the model
- Drift Detection in Feature Engineering Pipelines monitors the transformation applied to raw data to ensure consistency with the training pipeline
- Imbalanced Data Monitoring to ensure that class distributions remain similar to what the model was trained on to prevent model bias
- Univariate and Multivariate Statistics Monitoring using summary statistics for individual features or relationships between features to detect data shifts
Model Drift
Model drift occurs when the relationship between the input data and the model’s predictions change over time, leading to performance degradation. This can be due to changes in the underlying data distribution (data drift) or changes in the relationship between input features and the target variable (concept drift). Monitoring for model drift is essential to ensure that the model continues to provide accurate and relevant predictions in a changing environment.
Here are the key metrics to monitor for detecting and addressing model drift:
- Performance Metrics including accuracy, precision, recall, F1 score, AUC-ROC, MSE/RMSE
- Prediction Distribution Shifts to see if a model is no longer interpreting data as it did during training
- Target Distribution Shift to see if the real-world outcomes begin to deviate from what the model was trained on, which is an indication retraining is necessary
- Data Drift to see if input data has shifted from training data
- Feature Importance Drift shows if a model is relying on different patterns in the data, potentially causing performance issues
- Concept Drift showing if the model's learned patterns no longer apply to the current data
- Population Stability Index (PSI) measures change in distribution between two datasets, helping to quantify drift over time
- Jensen-Shannon (JS) Divergence to detect shifts in data distribution
- Kolmogorov-Smirnov (KS) Test to flag features that are experiencing data drift
- Hellinger Distance monitoring the distance between the training and production data distributions can help identify significant feature drift
- Confidence / Uncertainty Estimates to see if a model is encountering new, unfamiliar data that could lead to model drift
- Calibration Metrics (Brier Score) to measure the accuracy of probabilistic predictions
Model Configuration
Monitoring model configuration is essential for maintaining consistency, traceability, and ensuring that the model is functioning as intended. Model configuration includes parameters and settings related to model architecture, hyperparameters, feature engineering, and the environment in which the model is deployed. Changes in these configurations can significantly impact model performance, reproducibility, and interpretability.
Here are key metrics and elements to monitor for model configuration:
- Hyperparameters track the values of key hyperparameters that control the model’s learning process, giving visibility into unintended changes that may occur
- Model Versioning tracks the current model in production, ensuring traceability and allows for easy rollback if necessary
- Feature Engineering Pipeline monitors transformations applied to input features before they are fed into the model
- Input Data Schema because changes in the structure of input data can lead to model errors or incorrect predictions
- Feature Importance understanding shifts in feature importance between training and production can indicate issues with input data or feature processing
- Model Architecture understanding the structure of the model itself, getting visibility into changes that could impact performance and generalization
- Regularization Settings monitoring changes in regularization settings helps maintain model performance across different data environments
- Training Data Configuration understanding the configuration of training data ensures the model is trained on representative data and can generalize well in production
- Data Preprocessing Pipeline its important to maintain consistent preprocessing between training and production
- Model Output Thresholds monitoring output thresholds to ensure the model is making consistent decisions in production
- Batch Size and Learning Rate because changes in learning rate or batch size can affect the speed and quality of learning
- Random Seed and Initialization Settings ensuring consistency in random seed settings helps make model training and evaluation reproducible
- Model Deployment Environment because changes in the deployment environment can affect model performance or introduce compatibility issues
- Gradient Clipping and Optimizer Settings ensure that the optimization process remains stable during training, especially for deep learning models
- Checkpointing and Model Saving Configuration ensure that the latest stable model is saved and available for deployment
Prediction Drift
Prediction drift refers to the change in the distribution of the model's predictions over time compared to its initial, or expected, behavior. This can indicate underlying issues such as data drift, concept drift, or a change in real-world conditions that affect the model's performance. Monitoring prediction drift helps ensure that the model remains relevant and continues to make accurate predictions as the environment or data evolves.
Here are key metrics to monitor for prediction drift:
- Prediction Distribution Shift because a significant change in the distribution of predictions may indicate that the model is encountering new or different data than what it was trained on
- Class Proportion Monitoring (for Classification Models) helps detect imbalances in the predicted output over time, which could indicate drift in either the input data or the model itself
- Confidence Score Distribution because a shift in the confidence scores can indicate prediction drift
- Calibration Metrics because a change in calibration metrics can indicate that the model’s prediction probabilities are no longer reliable
- Concept Drift Detection to understand when the underlying relationships in the data that the model learned during training no longer hold true
- Kolmogorov-Smirnov (KS) Test for Predictions because a significant KS statistic can indicate that the distribution of predictions has shifted from the baseline
- Jensen-Shannon (JS) Divergence for early detection of shifts in prediction distributions
- Population Stability Index (PSI) to detect gradual changes in model predictions that could affect performance
- Performance Metrics over Time helps detect when the model is becoming less effective at making correct predictions
- Predicted Mean or Median Shift useful in regression tasks where the predicted values are continuous, a shift in the mean or median of predicted values can indicate a drift in the model’s predictions
- Threshold-based Monitoring for Classification Models helps ensure the model remains calibrated and relevant to the real-world problem
- False Positive and False Negative Rates because changes in FPR and FNR over time can indicate drift in how the model handles edge cases or changes in the underlying data distribution
- Prediction Confidence Interval Monitoring (for Regression Models) because wider or narrower confidence intervals can indicate that the model’s uncertainty about its predictions is changing
- Prediction Clustering or Mode Shift because a shift in the clustering or mode of predicted values may indicate that the model is consistently producing a different set of predictions
Security Issues
Monitoring for security issues is critical to ensure that the model and its surrounding infrastructure are protected from attacks that could compromise data integrity, model performance, or sensitive information. Since models can be vulnerable to various types of attacks, it’s important to track specific security-related metrics to detect and mitigate these threats.
Here are key metrics and approaches to monitor for security issues in machine learning models:
- Adversarial Attack Detection monitor input data for suspicious patterns, such as inputs that are very close to decision boundaries but lead to large changes in model output
- Data Poisoning Detection monitor training data for outliers, abnormal patterns, or inconsistent labeling that could indicate an attempt to poison the dataset
- Model Performance Degradation (Unexpected Shifts) set up thresholds for performance metrics and raise alerts if the model performance deviates significantly from normal levels
- Model Inversion Attack Detection monitor for abnormal query patterns where attackers may attempt to reconstruct sensitive data by sending a large number of queries to the model and analyzing the responses
- Model Extraction Attack Detection monitor API usage and query patterns for unusually high query rates or repeated requests that could indicate an attempt to extract the model
- Unusual API Traffic set thresholds for normal API usage and raise alerts if usage patterns deviate significantly from the norm
- Data Access Monitoring monitor data access logs for unusual or unauthorized access patterns, such as attempts to download or alter large portions of the dataset
- Input Data Validation set up validation checks on incoming data to ensure that it adheres to predefined rules (e.g., no negative values for age, valid date formats)
- Model Integrity Checks (Checksums / Hashes) use checksums or cryptographic hashes to verify that the deployed model has not been altered
- Monitoring for Exploits in Model APIs implement security controls such as rate limiting, input sanitization, and anomaly detection for API traffic
- Model Behavior Anomalies use anomaly detection techniques to monitor output predictions, set thresholds for acceptable prediction ranges or patterns and create alerts for unexpected outputs
- Model Access Control and Authentication Monitoring implement role-based access control (RBAC), multi-factor authentication (MFA), and log access attempts
- Resource Usage Monitoring (e.g., CPU, Memory) set thresholds for resource consumption and raise alerts when usage patterns deviate significantly from normal levels
- Data Leakage Detection monitor model predictions and logs to ensure that no sensitive information is being exposed
Common Challenges With Machine Learning Model Monitoring
Monitoring machine learning models in production can be challenging, much of which is due to the complexity of maintaining model performance, data integrity, infrastructure, and security over time. Unlike traditional applications or software products, machine learning models are dynamic, and their performance can degrade due to changing data, evolving business needs, or environmental factors.
Some of the most common issues include:
- Data Drift and Concept Drift Detection
- Lack of Immediate Ground Truth
- Performance Degradation Over Time
- Determining Thresholds for Alerts
- Complexity in Data and Model Pipelines
- Infrastructure and Scalability Issues
- Versioning and Model Rollouts
- Bias and Fairness Monitoring
- Security Vulnerabilities
- Explainability and Interpretability
- Automating Retraining and Updates
- Cross-Team Coordination and Ownership
- Managing Model Life Cycle and Compliance
Successfully monitoring machine learning models requires addressing these challenges through careful planning, automation, real-time metrics tracking, and coordination between teams to ensure model robustness, performance, and security throughout the model lifecycle.
Conclusion
Building a strategy for monitoring machine learning models is no small feat. There are many aspects of the model to consider, and many stakeholders that will need to be involved. But having a robust monitoring program will help ensure your model continues to provide value.
More Resources:
- Article: What Is AI Inference (And Why Should Devs Care?)
- Video: Building Apps with LLM Observability with Phillip Carter
- Article: The Data Pipeline is the New Secret Sauce by Jesse Robbins
- Article: Enterprise AI Infrastructure: Privacy, Maturity, Resources with BentoML
- Article: MLOps vs. Eng: Misaligned Incentives and Failure to Launch?
- Podcast: Monitoring Observability Mike Julian
- Video: Model Monitoring Tutorial with Amazon, Microsoft Researchers
Content from the Library
Generationship Ep. #42, Ziggy Stardust with Katie Hallett
In episode 42 of Generationship, Rachel Chalmers speaks with Katie Hallett about why she and her team decided to build a web...
Generationship Ep. #40, ExperimentOps with Salma Mayorquin of Remyx AI
In episode 40 of Generationship, Salma Mayorquin of Remyx AI unpacks the shift from traditional MLOps to ExperimentOps—a...