Synthetic Data for AI: Purpose and Use Cases
 Heavybit
Heavybit
Heavybit
What to Know About Synthetic Data for AI Programs
For software developers, large language models (LLMs) like ChatGPT can help modern coders write, test, and deploy with unprecedented speed and accuracy. Realizing the full potential for artificial intelligence use cases, particularly in highly regulated spaces, depends on access to massive amounts of relevant data of high quality, ideally managed by performant data pipelines.
And developers at startups may not have access to data at the scale they need. For those developers, there’s a solution: Synthetic data.
Synthetic data could soon outpace actual data as an input for AI. In 2023, Gartner identified synthetic data as one of its top five trends shaping the future of machine learning. By 2028, the firm projected, 80% of data for AI will be synthetically generated. Experts in highly regulated industries like healthcare suggest that “more and more, synthetic data is going to overtake and be the way people do AI in the future.”
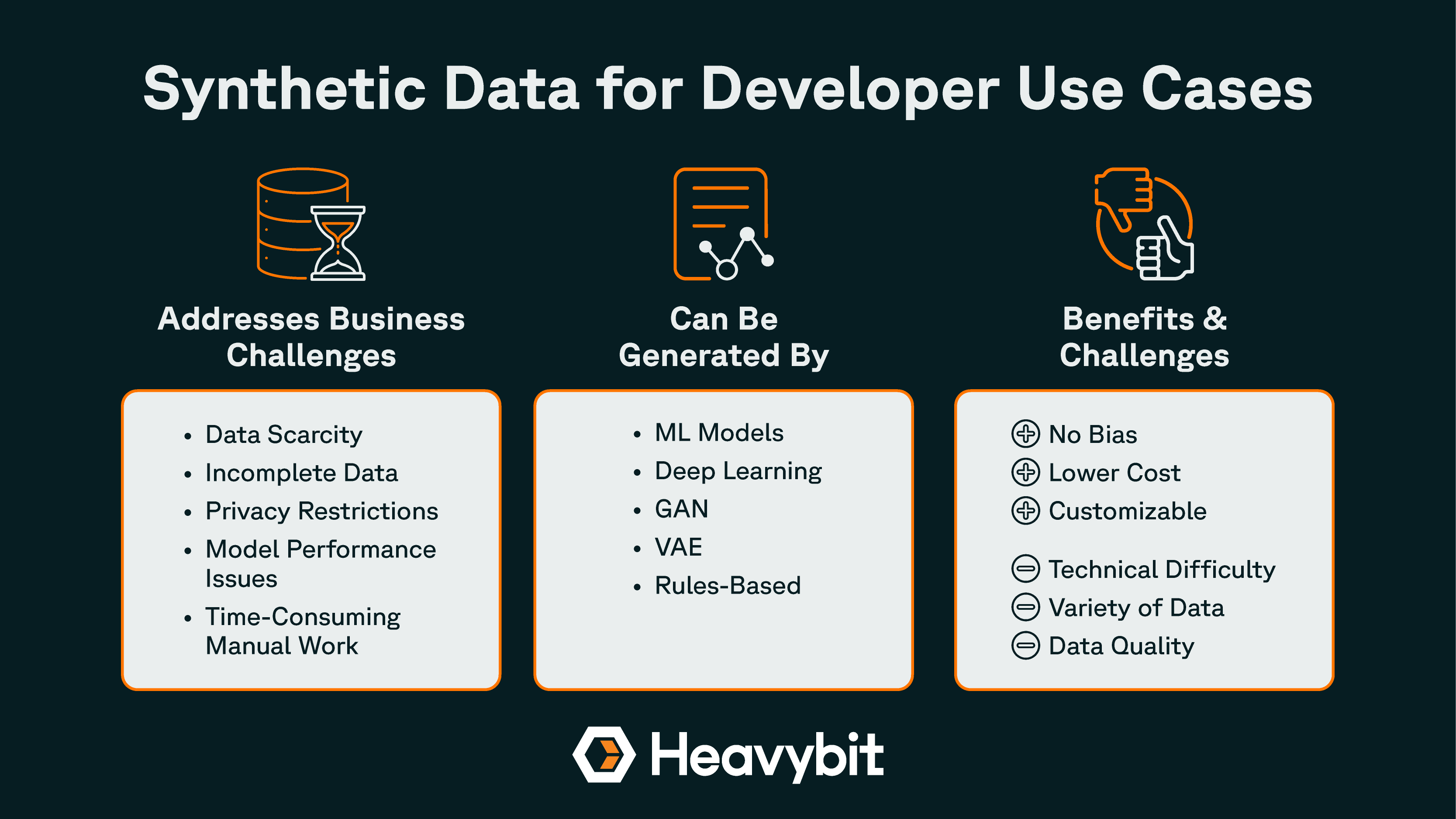
Heavybit: Synthetic Data for Developer Use Cases
>> Click to zoom in on this infographic
Synthetic data solves important data-related problems for devs.
What is Synthetic Data?
Synthetic data is artificially generated to meet a specific user need. Transformers, neural network architectures that transform inputs to outputs in ML processes, generally create synthetic data. The actual values in artificial data may need to go through anonymization, but the structure often mimics the shape of real datasets, using the same relationships, plot distributions, and statistical properties.
Synthetic data is not new. Physicists were creating synthetic audio a century ago, while major advances in autonomous driving over the last 20 years would have been impossible without synthetic data, which data science teams have used to test and refine algorithms without being constrained to a limited supply of data from real-world locations.
How Developers Use Synthetic Data in AI
In software development, the rapid emergence of AI and LLMs has made synthetic data an essential tool for developers throughout the ML lifecycle, particularly in regulated verticals including healthcare, finance, insurance, and manufacturing that handle sensitive data for customers or medical patients.
Synthetic data can speed up developer workflows in a number of ways:
Shoring Up Data Shortages
Data scarcity occurs for many reasons. Some organizations can’t attain real-world data at the scale their use case demands, including processes like recommendation engines, predictive systems, or natural language processing tasks. In highly regulated industries, data privacy requirements may limit developers’ access to production data or restrict them from dumping personal data directly into GPT.
For example, using publicly available data and simple Python scripting, a team of researchers at the Berlin Institute of Health built an accurate synthetic dataset modeling occurrence and outcomes from three rare diseases in the United States. The team built a data generation tool that addresses "the need to develop specific privacy-enhancing technologies for sharing rare disease data," the researchers wrote in a 2024 paper.
Augmentation of Incomplete or Inaccurate Data
Synthetic data can address other data deficiencies that developers face, such as simulating unusual real-world circumstances (rare diseases, for instance), swapping missing data points into incomplete datasets, and correcting inaccuracies in existing data to ensure ML algorithms produce the best results.
Augmenting existing data is essential to developing models that can identify counterfeit IT documents. Privacy regulations limit the amount of usable real-world data, and variations in the layout and content of ID documents create inconsistencies in the data that do exist. With fine-tuned generative language and vision models, you can create large synthetic ID datasets for training fraud detection algorithms.
Improving ML Model Performance
Synthetic data can help developers ensure their models are actually learning to recognize patterns, rather than just overfitting to limited training data. Introducing synthetic variations to ‘round out’ datasets prevents models from incorrectly attaining biases, such as drawing incorrect correlations from limited data, improving model performance on future data jobs.
One useful approach to improving model accuracy is the Synthetic Minority Oversampling Technique (SMOTE). It's a way of correcting for imbalance in original data by using nearest-neighbor algorithms to intentionally over-represent the minority class as you build training data. The result is a well-balanced synthetic dataset and, as a result, an ML model that's seen enough examples of minority results in training to identify them in production, which is vital for fraud detection.
Reducing Data Toil
Labeling data is a time-consuming and expensive process, especially for large datasets. Synthetic data often comes with automatic labels, reducing the need for manual annotation. For processes that require data in a particular format, such as tabular data or data arranged in a specific time series, automated tools that generate properly formatted synthetic data can also be powerful time savers.
In 2023, synthetic time-series data was key for the winners of a data-themed hackathon. The winning team used OpenAI's GPT-3.5 Turbo model to generate synthetic data projecting how friction would affect different materials over 31 points in time, based on a small set of existing historical data. Selective fine tuning ensured their model produced tabular data with the correct structure.
Generating Synthetic Data
There are several ways to go about the synthesis of synthetic data:
Model-Based Generation
One common way to create synthetic data is training machine learning models on your existing dataset to generate additional synthetic data. With this method, you can create a hybrid dataset that retains the statistical relationships and properties of the original dataset but adds synthetic elements.
This method’s particularly useful for filling gaps in existing data, extrapolating a large dataset from a small one, and scaling general-purpose generative AI models for more-specific uses.
Deep Learning Methods
Two types of deep learning models are widely used to create synthetic data: Generative adversarial networks (GANs) and variational autoencoders (VAEs), which can be used to generate either structured or unstructured data.
In a GAN, two network models collaborate: The generator creates new data while the discriminator assesses it. The generator applies the discriminator’s feedback to the next dataset it produces; that process repeats, persistently improving data quality until the user is satisfied.
VAEs are models in which encoders compress and compact actual data, which a decoder analyzes to generate synthetic data that recreates key characteristics of the original data. VAEs deliver datasets that are very similar to the existing data they’re mimicking.
Rules-Based Generation
If you have some certainty about how your synthetic dataset should diverge from the original, you can write it into rules and use Python to create a new dataset based on those rules. This method offers a great deal of control, but it scales poorly for complex datasets and cases where there are many intersecting rules.
How Can Synthetic Data Be Used for AI?
Synthetic data has become a crucial component in training AI models across multiple industries. Some key applications include:
- Protecting Privacy in Healthcare: Patient data is full of sensitive information, and healthcare providers are required by laws such as HIPAA to protect their privacy. Developers need access to data that’s as close as possible to actual real-world data in order to create new tools for identifying and treating illnesses. However, they are generally forbidden by law to feed unredacted electronic personal health information (ePHI) of patients into AI models for the purposes of testing. Synthetic data can give developers the data they need to innovate without exposing patients’ personally identifiable information (PII).
- Finding Fraud in Financial Services: Financial fraud detection requires vast amounts of transaction data. Like healthcare, the banking and payments industries are highly regulated and demand confidentiality. Synthetic data can replicate key elements of customer datasets without retaining identifiable information. ML models trained on such data are ideally suited to surface irregularities that often indicate fraudulent behavior.
- Simulating Complex Environments for Autonomous Vehicles: Long before they reach the road, AVs learn to drive in simulated road situations created by ML models. Automotive firms have access to massive amounts of real-world sensor data. Adding synthetic data lets team simulate unusual scenarios that AVs must experience to safely navigate the road. Emerging use cases include replicating crashes to evaluate safety features.
Benefits of Synthetic Data for AI
Synthetic data doesn’t just have to be an option when real datasets are unavailable or inaccessible. It has several advantages over authentic data, making it an attractive option for startups and software developers:
1. No Bias
Bias in your underlying data can nullify whatever benefits you stand to gain from machine learning. And bias is pretty common in actual datasets: over- or under-representation of demographic groups in sampling, mislabeling of data elements, and the conscious or unconscious biases of the people who originally collected the data all occur.
Synthetic data can account for biases up front. Important optimization work like demographic balancing can offset inequities in the dataset you’re augmenting or imitating, and building bias mitigation into your GAN or VAE setup can ensure your synthetic dataset is free from disparities.
2. Lower Cost
Collecting, cleaning, and labeling real-world data is expensive, time-consuming, and resource-intensive. Manual data collection requires hiring data scientists, setting up infrastructure, and ensuring compliance with data regulations. In contrast, synthetic data can be generated programmatically, reducing costs and allowing startups to focus on innovation rather than data acquisition.
While there are commercial products like Amazon Bedrock, Microsoft’s AI Azure Foundry, and specialist startups like Tonic that create synthetic data via API, for cost-conscious organizations, there are also open-source tools that generate synthetic data.
3. Customizable
Synthetic data can be tailored to specific needs, making it more flexible than real-world data. Developers can generate datasets that include rare events, underrepresented scenarios, or domain-specific requirements, ensuring that AI models are trained on highly relevant data. Every element of a synthetic dataset is under your control.
Challenges in Using Synthetic Data for AI
Synthetic data is powerful, but it’s not perfect. But when you know what challenges to expect, you can build monitoring and mitigation into your plans. Here are a few of the complexities that come with using synthetic data for AI:
1. Technical Difficulty
Generating high-quality synthetic data requires advanced technical expertise to set and interpret benchmarks properly. Developers must be proficient in Python, machine learning frameworks, and generative modeling techniques like GANs or diffusion models. Additionally, ensuring that synthetic data maintains statistical fidelity with real-world data requires careful validation and monitoring.
2. Variety of Data
Synthetic data generation works well in structured environments but has limitations in multimodal scenarios. For example, AI models that rely on a combination of images, text, video, and audio may struggle to use purely synthetic data for computer vision or Internet of Things use cases. Developers need to carefully evaluate whether synthetic data alone is sufficient or if it should be combined with real-world data.
3. Data Quality
The quality of synthetic data depends on the sophistication of the generation process. Poorly generated synthetic data can be plagued by the same biases and inaccuracies as real-world datasets, leading to AI models that perform poorly in production. To ensure reliability, startups should consider investing in data quality checks, hiring professionals who can validate their synthetic training datasets before training AI models on them.
Final Thoughts
Synthetic data is a game-changer for AI development, offering scalability, privacy protection, and cost savings. While it comes with technical challenges, its benefits far outweigh the drawbacks, especially for startups looking to accelerate AI innovation. If you're a developer working on AI projects, now is the time to explore how synthetic data can help you build smarter and more efficient models.
More Resources
Content from the Library
The Role of Synthetic Data in AI/ML Programs in Software
Why Synthetic Data Matters for Software Running AI in production requires a great deal of data to feed to models. Reddit is now...
Regulation & Copyrights: Do They Work for AI & Open Source?
Emerging Questions in Global Regulation for AI and Open Source The 46th President of the United States issued an executive order...
How to Properly Scope and Evolve Data Pipelines
For Data Pipelines, Planning Matters. So Does Evolution. A data pipeline is a set of processes that extracts, transforms, and...