AI Inference: A Guide for Founders and Developers
 Andrew ParkEditorial Lead, Heavybit
Andrew ParkEditorial Lead, Heavybit
What Is AI Inference (And Why Should Devs Care?)
AI inference is the process of machine learning models processing previously unseen data, which formulates a prediction as the models’ output.
Broadly speaking, inference includes both reasoning–making sense of and drawing conclusions from new data based on pre-set rules or observations–as well as responses, the delivery of an output that is ideally accurate and free of hallucination or bias.
Large language models (LLMs) typically work with text-based data, and classify strings of characters, whole words, or entire sentences into multi-character tokens, which LLMs use as basic data units on which to perform inference. The ability of LLMs to rapidly spin up large amounts of content is effectively the basis of modern generative AI (GenAI).
The term “next token prediction” is used as a sometimes-cynical shorthand to refer to AI inference in LLMs. To skeptics, a model may seem accurate if it can take a previously-unseen prompt and accurately predict appropriate tokens to populate the response–providing responses that are relevant, contextually appropriate, and factual.
Of course, there’s a little more going on under the hood. As we’ll cover shortly, inference can be important for developers of artificial intelligence applications due to compute costs as well as for performance reasons. In this article, in addition to covering what AI inference is, we’ll also focus on:
- AI Inference In-Depth: Process Deep-Dive, Inference Types, Metrics
- Where Inference Fits Into AI App Dev: Differences from AI Training, Fine-Tuning
- How Inference Matters for AI App Development
- What to Know About Hardware, Configurations, and Costs
- AI Inference for Founders and Dev Teams
- Inference Challenges to Consider
A Closer Look at AI Inferencing
Below, we’ll cover the nuts and bolts of inference from a process standpoint, different flavors of inference, and common performance metrics.
AI Inference, Step-By-Step
In crude and incomplete terms, you could compare the process of how inference works to the process of human “thought” in a few ways. Inference, like human thought, involves pattern-matching, contextual understanding, and decision-making–what happens after people get all the facts about a situation, then weigh their options to come to a conclusion.
If deep learning is the machine language equivalent of human thought–based on ML neural networks that model the human mind–inference is effectively the execution step.
However, ML models lack many intrinsically human aspects of cognition, like understanding the meanings or intent behind actions, thoughts, or decisions. They also lack the intuition (and creativity) to fill in broader contextual gaps. Ultimately, what models do is calculate values using complex machine learning algorithms.
In most cases, typical AI inference jobs require:
- A specific problem or challenge to resolve
- A production-ready data set
- An appropriate, production-ready model(s)
- For strong performance, models should be pre-trained before inference jobs
- In some cases, teams can optimize performance with fine-tuning prior to inference
- An inference pipeline to process data and prepare it for model inference
1. Embedding Feature Vectors
To prime their model to process their data set, teams will embed feature vectors–which contain individual, measurable feature values that represent the data to be processed–into their model. The model will view the features in the embedding as characteristics to consider when forming predictions as it passes transformed data through the various layers of the model.
2. Apply Weighting From Pre-Trained Model
The model then applies the pre-trained model’s weighting–which emphasizes certain variables over others as contextually appropriate–to the embedded vector, to then be used by the model to generate its prediction.
3. Apply Activation Function
The activation function turns the weighted sum of the previous step into an output signal for the next layer by applying functions such as the ReLU or logistic function.
4. Final Transformation in Output Layer (Plus Post-Processing)
After applying various functions, the model moves to the output layer, making its last transformations to produce the final response. (In some cases, to improve the quality or relevance of a response, it may also be necessary to apply additional post-processing work to the data, like pruning, rule filtering, or knowledge integration.)
5. Output Response
After applying various functions, the model moves to the output layer, making its last After the response has completed processing and any necessary clean-up work, the model outputs it to the users.
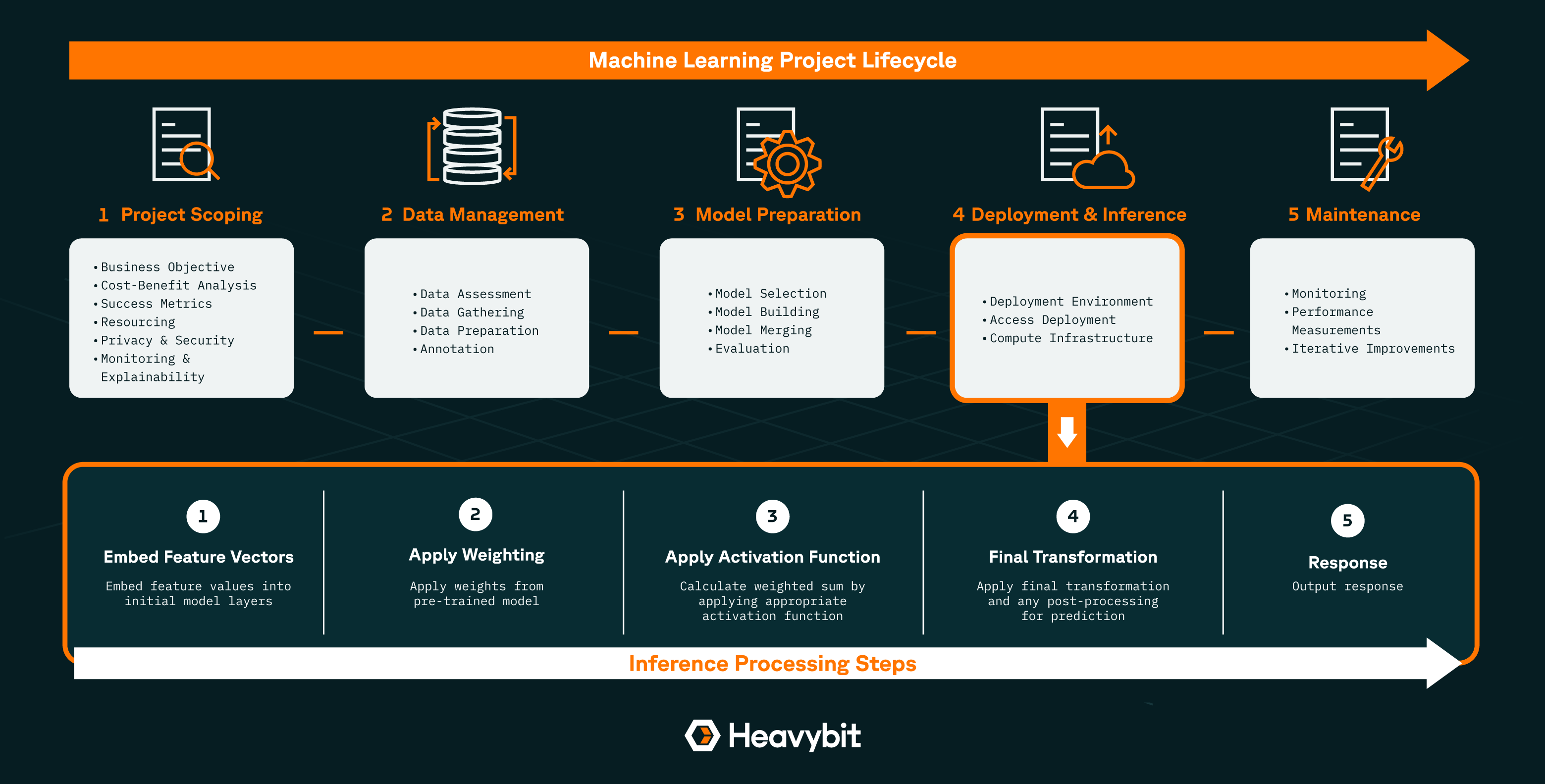
Inference along the Machine Learning Project Lifecycle - Heavybit
>> Click to zoom in on this infographic
Inference takes place in an ML project after all the data and model engineering are complete.
Common AI Inference Types
Not all inference jobs are equal. Here are some of the most common types of inference jobs, with examples of potential use cases and verticals.
Batch
Routine-but-regular jobs are often best suited to batch inference–inference jobs run on a set schedule that pull from a regularly-updated feature store and save responses in a data repository or object store. Batch inference makes the most sense for ongoing, non-urgent processes such as generating regular reporting on an hourly or daily basis.
Online
For on-demand use cases that require timely responses to prompts, online inference (also known as dynamic or real-time inference) may be a good fit. In this case, the model effectively performs inference on demand, ideally with little to no latency, often to pull features from an existing feature store or generate responses for use in another model.
Online inference is seeing increased real-world usage in verticals like customer service via chatbots similar to ChatGPT, as well as in verticals like finance for economic projections and forecasting, and the healthcare and insurance ecosystems for providing quick responses to health record requests and insurance claims.
Stream
Stream processing inference is best suited in a stream processing application that ingests data or events from another source. Stream processing inference is a good fit for machine-to-machine applications, such as streamed-in captured from IoT devices.
Common AI Inference Metrics
Some of the most common metrics associated with AI inference include:
Latency
Latency refers to the speed at which machine learning models can complete inference. Latency can depend on how much compute resources are available for a specific job, how finely tuned a model is, and how optimized a model is for that job.
Advanced techniques to speed up inference include removing layers from your model, model quantization to reduce weights with lower-precision data (which can effectively shrink models and free up resources), and mixture-of-experts, which divides tasks across different models for better performance. (We’ll cover more on optimization across hardware and models shortly.)
Latency is typically measured in milliseconds (ms), but may use longer timescales depending on use cases.
Throughput
Throughput refers to the number of predictions your machine learning model(s) can produce within a specified period of time without failing (though from an uptime standpoint, it may also consider the number of requests your models can accommodate across various AI workloads within a time period).
In an ideal world, your inference latency is always close to zero while your throughput is as high as possible. When considering throughput and latency for your use case, you may need to trade-off one for the other, depending on your data needs. Throughput is commonly measured in predictions per second (PPS), though it may also consider requests per second (RPS).
Accuracy*
Accuracy is the most common performance metric for machine learning models, though it technically assesses the results of inference*, not the performance. That is, accuracy is the quality of your model’s response afterward–and not the inference process itself. Accuracy is typically measured as a percentage between 0 (highly inaccurate) and 1 (perfectly accurate).
Where Inference Fits Into AI
Inference is generally one of the last steps in the lifecycle of a typical machine learning project–it happens after you’ve compiled an appropriate data set and evaluated a model for fit.
Note: How Inference Differs From Training and Fine-Tuning
As we’ll cover below, inference is different from model training, and fine-tuning (which is itself a kind of AI training). In the standard ML project lifecycle, training and fine-tuning happen before inference:
Training models “teaches” the machine learning algorithms to recognize patterns and formulate predictions. Most of the “largest” models in the world, trained on large data sets with billions of training parameters used the content of the entire open internet as training data. Trained AI models generally offer better, more-accurate predictions with fewer errors and more scalability.
Fine-tuning further trains AI models beyond the pretrained state with additional training on a purposely smaller, more-focused data set. Fine-tuning further improves performance by utilizing transfer learning–using the model’s existing knowledge to learn–while using fewer compute resources and executing with low latency.
Ideally, ML projects run inference on a data set using a model that has already been trained and fine-tuned to optimize accuracy and minimize resource costs.
AI Inference in the Lifecycle of a ML Project: Step-by-Step
1. Project Scoping
Properly planning a ML project, particularly a large-scale one, requires an in-depth assessment of how feasible it is, how costly it is, and whether you can properly resource it. These are some of the most crucial aspects of AI systems in production:
- Business Objective: Specifically scoping the problem to be solved
- Cost-Benefit Analysis: Whether the results will justify a full ML project lifecycle
- Success Metrics: Including response accuracy, ROI, and other business results
- Resourcing: Is the project feasible funds, team members, and compute required?
- Privacy and Security: Will this project be compliant with your team’s and customers’ requirements?
- Monitoring and Explainability: In production, how will the project be monitored? And will results (and potential model drift) be explainable?
2. Data Management
Once a project is scoped and a business challenge has been identified, MLOps and data engineering teams set about compiling the appropriate data set to use as inputs into their model(s). The process typically involves:
- Data Assessment: Whether data on hand is sufficient, needs acquiring, or should be augmented/replaced with synthetic data
- Data Gathering: Collecting, acquiring, or synthesizing additional data
- Data Prep and Annotation: Chunking data by splitting into smaller subsets, filtering, and annotating to optimize performance
3. Model Preparation
After you’ve prepared your data, you’ll need to prepare your model(s) for the job. The process can include the following steps:
- Model Selection: Choosing a pre-built model based on estimated performance
- Model Building: Building out your model(s) for use based on in-house algorithms or off-the-shelf models
- Model Merging: Potentially combining multiple models with different strengths into one to leverage the different strengths of each
- Model Evaluation: Assessing the performance of your model(s) for performance and metrics before deployment
4. Model Deployment (and Inference)
Once your data and model(s) are ready, it’s time to deploy. Deploying a ML project via an AI model has several requirements, including:
- Deployment Environment: Including locally (on-device) or via Cloud
- Access: An API, plugins, dashboard, or some other means to access your model(s)’ output
- Compute Infrastructure: To run inference, you’ll need silicon that provides sufficient compute power and storage
5. Maintenance
Post-deploy, you will, like with any other production software, need to monitor your model to ensure it’s performing properly, not overconsuming resources, and providing results that meet your metrics (and ideally make customers happy).

META unveils Llama-3, a massive 405 billion-parameter LLM that reportedly cost $700M to train. Image courtesy TechCrunch
Why is AI Inference Important?
For machine learning projects, inference is effectively where the rubber hits the road (or where the data sets hit the model). It’s the essential step in which models process prompts and data, leading to the response as an output.
When thinking about how to properly scope a real-world use case for AI systems, it’s important to consider these aspects of inference:
Decision-Making
For all intents and purposes, inference is the step at which your model makes its decisions, having ingested data and formulated predictions. The resourcing and speed of your inference can affect the quality of your responses. Depending on your use case, inferencing issues could mean unnoticeable delays in chatbot responses or disastrous decisions from self-driving cars.
Scalability
As mentioned, inference bottlenecks can significantly affect the performance of an ML project. Inference architecture that isn’t scalable due to poor load balancing of compute resources can have a seriously adverse effect on user experience for applications that are expected to be responsive.
Cost
The high cost of AI has been widely reported. Scarce compute resources, the hardware (and data centers) to run it on, and a growing need for energy infrastructure to power it make for a high total cost of ownership. For use cases that regularly run huge batches of data, inference can quickly become very expensive. (We’ll cover more on how to manage costs shortly.)
How Improved Hardware Will Impact AI Inference
In the current state of play, teams primarily run their inference on graphical processing units–hardware chips originally built to render high-end computer graphics with their processing power. While traditional cloud compute is run on CPU, the sheer horsepower of graphics processors make them well-suited for heavy-duty ML data jobs.
At the time of this writing, GPU manufacturer Nvidia enjoys a significant market lead, producing the most sought-after (and difficult-to-procure) products. But there are ongoing developments in (and around) the hardware market that may change the cost and performance outlook of AI inference in the future:
Increased Competition in the Hardware Market
Competitors like AMD are investing heavily in capturing more market share from Nvidia. Other vendors are also developing alternatives to GPUs, including processors that were purpose-built for AI from the ground up.
Given the fierce competition and the economic realities of building high-end hardware at this scale, it’s not clear that Moore’s Law will continue indefinitely. However, the tech sector has clearly recognized the challenge of costly compute resources.
Research: Lower-Cost Inference Techniques in Model and Hardware Architecture
Researchers are increasingly spending cycles finding alternative inference and model building techniques to conserve compute and cut costs. Where popular research hub Arxiv’s AI projects used to focus purely on scientific advancement, an increasing number of journals now focus on discovering and optimizing operational techniques to increase efficiency, including:
Mixture-of-Experts
Mixture-of-Experts (MoE) utilizes specialized models to process different jobs of a machine learning project, rather than using a single large model. A MoE project sees multiple, smaller instances of computations (rather than a single big job), reducing the amount of necessary resources and potentially speeding up the results as well.
Pruning
Decision tree pruning removes redundant parameters and weights, effectively reducing the number of computational layers through which a model must pass data, requiring less memory usage overall.
Distillation
Knowledge distillation is a technique that utilizes transfer learning such that a large trained AI model, trained on many parameters “teaches” a smaller, simpler model. With proper distillation, smaller models can mimic the high performance of its larger counterparts using far less compute resources.
Sparse Models
Sparse models are an alternative to large models which, rather than consider billions of unique AI training parameters, consider most of its parameters to equal zero–and therefore activate far fewer of them, spending fewer resources overall when running inference.
Quantization
Quantization reduces the precision of numbers in a model’s calculations–for example, replacing 32-bit floating-point numbers with 8-bit integers. As a result, models require less memory storage and can operate better on lower-end hardware, such as edge computing devices.
Gradient Checkpointing
Gradient checkpointing reduces the amount of results the model stores while performing computations, reducing overall memory usage, but potentially increasing runtime as a tradeoff.
New Configurations: Edge Computing On-Device
While the earlier days of LLMs seemed to be an arms race between vendors trying to train larger and larger models with hundreds of billions of parameters, users are finding surprisingly strong performance with smaller models that utilize far fewer parameters. (As of the time of this writing, “small” models come down to as low as 3B to 7B.)
Smaller models mean less compute resources needed, which means more viability when run locally on the edge. On-device model operations dramatically reduce compute costs and significantly improve data privacy, as users deal entirely with private data locally without having to share over any kind of potentially vulnerable network.
What Founders and Developers Need to Know About AI Inference
For those building AI applications, particularly on top of LLMs, inference can matter a lot. So can questions like whether to go with a closed-source, open-weight model from an API provider or go with open source–with the former providing a more user-friendly experience and more in-depth support, and the latter providing enormous flexibility and variety of choices.
The most successful AI apps built over top or within AI systems provide value and an excellent user experience by:
Performing at Acceptable Latency
Particularly for use cases that are intended to “improve productivity” or are otherwise time bound, the model underpinning your AI application must be able to run its inference processes and deliver responses within an acceptable response window.
For AI applications that customers expect to run quickly, such as rapid generation tools for code or documentation, lag means a negative user experience that customers will not love.
Performing Reliably (and Accurately)
There are several reasons why an app built on top of an AI model might fail. For example, a project might be more resource-intensive than anticipated, using up all the allotted compute resources, and–unable to push through those last few AI workloads–slowing throughput to a crawl until the job fails.
While building AI solutions is still a relatively new practice, 55% of Americans reportedly “don’t trust” AI models, or the information they provide. Ensuring your product consistently provides accurate predictions is table-stakes; ensuring inference won’t fail is also important.
Performing Economically
Inference isn’t cheap, especially at scale. If you’re building a product to tackle a highly inference-intensive use case, you may be looking at extremely high costs for compute resources that jeopardize the viability of the product itself. Unfortunately, the expensive racks of GPUs at the data centers aren’t free.
To bring down inference costs and conserve compute, it’s a good idea to investigate fine-tuning, using “smaller” (fewer-parameter) models, or using advanced techniques such as mixture-of-experts–splitting operations across multiple models to improve performance and reduce costs. Read more in this interview on AI inference resourcing for the enterprise.

UK chip manufacturer Arm celebrates a massive valuation spike due to AI demand. Image courtesy BBC
Challenges with AI Inference
Along with the issues we’ve covered above, here are some additional inference challenges that teams may encounter when trying to manage ML programs over time:
Subject-Matter Expertise (or Lack Thereof)
While organizations expect engineers to put software products into production, very few developers have machine learning PhDs. Understanding the finer points of inference, deep learning, and neural networks is traditionally the domain of academically-trained data scientists, though as more AI systems get productionized, devs will likely gain more expertise over time.
Expanding Project Complexity
The economic realities of running gigantic data jobs on gigantic models (and incurring gigantic usage bills) have already set in for many organizations. As more orgs look for opportunities on compute and cost optimization, they’ll also look to outpace competitors who may be on similar stages in their own learning journeys.
As a result, the future of AI systems in production may lie in compound AI systems, which employ multiple tools and models to efficiently puzzle out use cases with optimal performance.
Performance and Cost
For better or for worse, modern AI has earned a reputation for speedy responses. Many types of customers will expect applications built on LLMs and other AI systems to be fast, performant, and reliable.
Likewise, companies that build AI solutions to serve inference-heavy use cases may potentially incur significant compute costs–and should look for as many opportunities as possible to get more efficient and use less compute, memory, and energy where possible.
Conclusion
Hopefully, this article has helped you better understand what AI inference is and its significance to software development and building AI products. Here are more resources to learn about the practical approaches teams are using to create AI software.
- Article: The Data Pipeline Is the New Secret Sauce by Jesse Robbins
- Article: Enterprise AI Infrastructure: Privacy, Maturity, Resources
- Article: Digging Deeper into Building on LLMs with Phillip Carter
- Article: How to Launch an AI Startup with Alyss Noland
- Article: Incident Response and DevOps in the Age of Generative AI
- Article: AI’s Hidden Opportunities with Shawn “swyx” Wang
- Article: Who Are the Developers Working on Generative AI Projects?
- Article: How LLM Guardrails Reduce AI Risk in Software Development
- Article: The Future of Software Development in the Age of AI
Content from the Library
The Future of Coding in the Age of GenAI
What AI Assistants Mean for the Future of Coding If you only read the headlines, AI has already amplified software engineers...
Enterprise AI Infrastructure: Compliance, Risks, Adoption
How Enterprise AI Infrastructure Must Balance Change Management vs. Risk Aversion 50%-60% of enterprises reportedly “use” AI,...